Airflow#
Note
Download the full code example from the following link
Apache Airflow is an open-source workflow management system. It is commonly used to automate data processing, data science, and data engineering pipelines.
This tutorial demonstrates how deepchecks can be used with Apache Airflow. We will run a simple Airflow DAG that will
evaluate the Adult dataset from the UCI Machine Learning Repository. The DAG will run the
data_integrity() and the model_evaluation()
suites on the Adult data and a pre-trained model.
from datetime import datetime, timedelta
import os
from airflow import DAG
from airflow.operators.python import PythonOperator
import joblib
import pandas as pd
from deepchecks.tabular.datasets.classification import adult
dir_path = "suite_results"
# For demo only. Replace that with a S3/GCS other than local filesystem
data_path = os.path.join(os.getcwd(), "data")
Defining the Data & Model Loading Tasks#
def load_adult_dataset(**context):
df_train, df_test = adult.load_data(data_format='Dataframe')
try:
os.mkdir(data_path)
except OSError:
print("Creation of the directory {} failed".format(dir_path))
with open(os.path.join(data_path, "adult_train.csv"), "w") as f:
df_train.to_csv(f, index=False)
context["ti"].xcom_push(key="train_path", value=os.path.join(data_path, "adult_train.csv"))
with open(os.path.join(data_path, "adult_test.csv"), "w") as f:
df_test.to_csv(f, index=False)
context["ti"].xcom_push(key="test_path", value=os.path.join(data_path, "adult_test.csv"))
def load_adult_model(**context):
from deepchecks.tabular.datasets.classification.adult import load_fitted_model
model = load_fitted_model()
with open(os.path.join(data_path, "adult_model.joblib"), "wb") as f:
joblib.dump(model, f)
context["ti"].xcom_push(key="adult_model", value=os.path.join(data_path, "adult_model.joblib"))
Note
The dataset and the model are saved in the local filesystem for simplicity. For most use-cases, it is recommended to save the data and the model in a S3/GCS/other intermediate storage.
Defining the Integrity Report Task#
The data_integrity() suite will be used to evaluate the train and production
datasets. It will check for integrity issues and will save the output html reports to the suite_results directory.
def dataset_integrity_step(**context):
from deepchecks.tabular.suites import data_integrity
from deepchecks.tabular.datasets.classification.adult import _CAT_FEATURES, _target
from deepchecks.tabular import Dataset
adult_train = pd.read_csv(context.get("ti").xcom_pull(key="train_path"))
adult_test = pd.read_csv(context.get("ti").xcom_pull(key="test_path"))
ds_train = Dataset(adult_train, label=_target, cat_features=_CAT_FEATURES)
ds_test = Dataset(adult_test, label=_target, cat_features=_CAT_FEATURES)
train_results = data_integrity().run(ds_train)
test_results = data_integrity().run(ds_test)
try:
os.mkdir('suite_results')
except OSError:
print("Creation of the directory {} failed".format(dir_path))
run_time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
train_results.save_as_html(os.path.join(dir_path, f'train_integrity_{run_time}.html'))
test_results.save_as_html(os.path.join(dir_path, f'test_integrity_{run_time}.html'))
Defining the Model Evaluation Task#
The model_evaluation() suite will be used to evaluate the model itself.
It will check for model performance and overfit issues and will save the report to the suite_results directory.
def model_evaluation_step(**context):
from deepchecks.tabular.suites import model_evaluation
from deepchecks.tabular.datasets.classification.adult import _CAT_FEATURES, _target
from deepchecks.tabular import Dataset
adult_model = joblib.load(context.get("ti").xcom_pull(key="adult_model"))
adult_train = pd.read_csv(context.get("ti").xcom_pull(key="train_path"))
adult_test = pd.read_csv(context.get("ti").xcom_pull(key="test_path"))
ds_train = Dataset(adult_train, label=_target, cat_features=_CAT_FEATURES)
ds_test = Dataset(adult_test, label=_target, cat_features=_CAT_FEATURES)
evaluation_results = model_evaluation().run(ds_train, ds_test, adult_model)
run_time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
evaluation_results.save_as_html(os.path.join(dir_path, f'model_evaluation_{run_time}.html'))
Creating the DAG#
After we have defined all the tasks, we can create the DAG using Airflow syntax. We will define a DAG that will run every day.
with DAG(
dag_id="deepchecks_airflow_integration",
schedule_interval="@daily",
default_args={
"owner": "airflow",
"retries": 1,
"retry_delay": timedelta(minutes=5),
"start_date": datetime(2021, 1, 1),
},
catchup=False,
) as dag:
load_adult_dataset = PythonOperator(
task_id="load_adult_dataset",
python_callable=load_adult_dataset
)
integrity_report = PythonOperator(
task_id="integrity_report",
python_callable=dataset_integrity_step
)
load_adult_model = PythonOperator(
task_id="load_adult_model",
python_callable=load_adult_model
)
evaluation_report = PythonOperator(
task_id="evaluation_report",
python_callable=model_evaluation_step
)
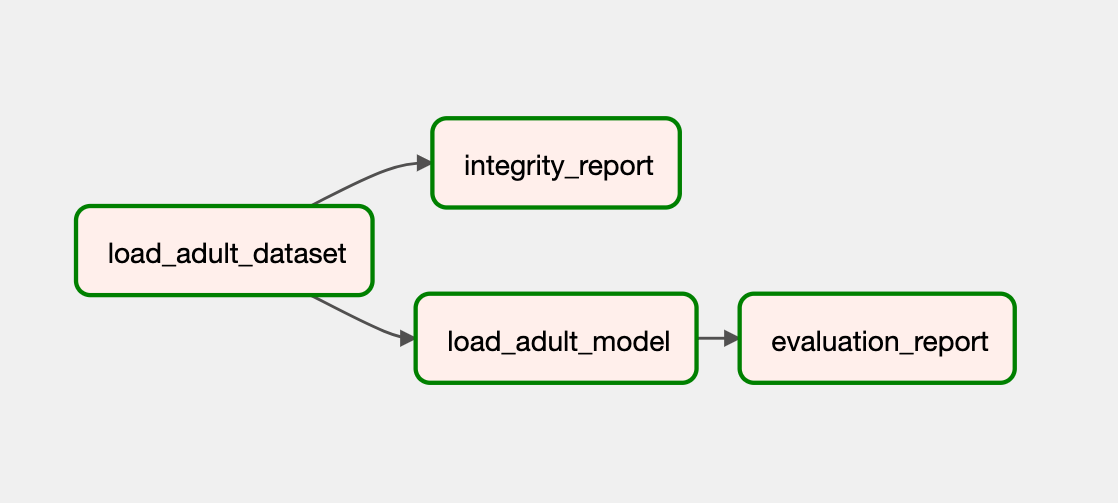
load_adult_dataset >> integrity_report
load_adult_dataset >> load_adult_model >> evaluation_report
And that’s it! In order to run the dag, make sure you place the file in your DAGs folder referenced in your
airflow.cfg. The default location for your DAGs is ~/airflow/dags.
The DAG is scheduled to run daily, but the scheduling can be configured using the schedule_interval property.
The DAG can also be manually triggered for a single run by using the following command:
airflow dags backfill deepchecks_airflow_integration --start-date <some date in YYYY-MM-DD format>