Note
Go to the end to download the full example code
Predicting Loan Defaults (Classification)#
In this Demo we are using an adaptation of the Lending Club loan data dataset to show how you can use Deepchecks to monitor and identify issues in a Loan Default prediction task.
You are a Data Scientist in a renowned bank, and you are tasked with identifying customers that are likely to default on their mortgage loan. In this example we’ll use Deepchecks to quickly detect some data integrity issues that occur over the lifetime of the model, and we’ll see how Deepchecks can alert us about potential model deterioration that can be caused by increasing interest rates, even while labels are not yet available.
Tip
To see how Deepchecks Monitoring is used, you can skip right to Analyzing Using Deepchecks
Setting You Up on Deepchecks#
Installation & API key#
In order to work with Deepchecks Monitoring, you need to:
Install with
pipthe deepchecks-client SDKLog in to the Deepchecks Monitoring app and create an organization
Obtain an API key from the app
For more details, please refer to the Quickstart.
Creating a Client#
To work with Deepchecks Monitoring we first instantiate a client object.
import os
from deepchecks_client import DeepchecksClient
# Note: add an environment variable DEEPCHECKS_API_TOKEN and set it to your API token's value. Alternatively (not
# recommended for security reasons) copy-paste your token string here, instead of retrieving it from the environment
# variable.
token = os.getenv('DEEPCHECKS_API_TOKEN')
# Point the host to deepchecks host url (e.g. https://app.deepchecks.com. Save it to an environment variable,
# or alternatively copy-paste it here directly)
host = os.getenv('DEEPCHECKS_API_HOST')
# Create a DeepchecksClient with relevant credentials
dc_client = DeepchecksClient(host=host, token=token)
We’ll use this object during the remainder of this example.
Creating a Model & Model Version#
In this section we’ll create a model and a model version, using the training data as the reference. Reference data is a dataset to which we wish to compare our production data stream. To learn more about models and model versions, and other important terms in Deepchecks please refer to the Concepts guide.
Getting the Data#
We’ll start by downloading the training data and model we’ll be using for this example. In our example we already saved the training data for this use case in a csv file on figshare.
import pandas as pd
train_df = pd.read_csv('https://figshare.com/ndownloader/files/39316160')
train_df.head(2)
So what do we have? Let’s note the special columns in our data:
issue_d - The timestamp of the sample
id - the id of the loan application
loan_status - Our label, which is the final status of the loan. 0 means “payed in full”, and 1 are defaults.
All the other columns are features that can be used by our model to predict whether the user will default or not.
Data Schema#
A Schema file contains the description of the data (features and additional data) associated with a model version. To learn more about creating a schema, please refer to the Tabular Setup guide.
It is highly recommended to review the created schema file before moving forward to creating the model version.
In order to create a schema file, the easiest way is to first define a deepchecks Dataset object, which contains the actual data (DataFrame) together with metadata about the role of each column.
from deepchecks.tabular import Dataset
features = ['sub_grade', 'term', 'home_ownership', 'fico_range_low',
'total_acc', 'pub_rec', 'revol_util', 'annual_inc', 'int_rate', 'dti',
'purpose', 'mort_acc', 'loan_amnt', 'application_type', 'installment',
'verification_status', 'pub_rec_bankruptcies', 'addr_state',
'initial_list_status', 'fico_range_high', 'revol_bal', 'open_acc',
'emp_length', 'time_to_earliest_cr_line']
cat_features = ['sub_grade', 'home_ownership', 'term', 'purpose', 'application_type', 'verification_status', 'addr_state',
'initial_list_status']
dataset_kwargs = {
'features': features,
'cat_features': cat_features,
'index_name': 'id',
'label': 'loan_status',
'datetime_name': 'issue_d'
}
train_dataset = Dataset(train_df, **dataset_kwargs)
We’ll create the schema file, and print it to show (and validate) the schema that was created.
from deepchecks_client import create_schema, read_schema
schema_file_path = 'schema_file.yaml'
create_schema(dataset=train_dataset, schema_output_file=schema_file_path)
read_schema(schema_file_path)
Schema was successfully generated and saved to schema_file.yaml.
{'additional_data': {}, 'features': {'addr_state': 'categorical', 'annual_inc': 'numeric', 'application_type': 'categorical', 'dti': 'numeric', 'emp_length': 'numeric', 'fico_range_high': 'numeric', 'fico_range_low': 'numeric', 'home_ownership': 'categorical', 'initial_list_status': 'categorical', 'installment': 'numeric', 'int_rate': 'numeric', 'loan_amnt': 'numeric', 'mort_acc': 'numeric', 'open_acc': 'numeric', 'pub_rec': 'numeric', 'pub_rec_bankruptcies': 'numeric', 'purpose': 'categorical', 'revol_bal': 'numeric', 'revol_util': 'numeric', 'sub_grade': 'categorical', 'term': 'categorical', 'time_to_earliest_cr_line': 'numeric', 'total_acc': 'numeric', 'verification_status': 'categorical'}}
Note
For conveniently changing the auto-inferred schema it’s recommended to edit the textual file with an app of your choice.
After editing, you can use the read_schema
function to verify the validity of the syntax in your updated schema.
Feature Importance#
In order to provide the best analysis and alerts, we should let Deepchecks know about the relative importance of the features to the model’s prediction. In this example we’ll load our model and get its feature importance, but these can be easily calculated using deepchecks, or other methods (such as SHAP). Note that the feature importance values should be normalized to sum to 1.
import joblib
from urllib.request import urlopen
with urlopen('https://figshare.com/ndownloader/files/39316172') as f:
model = joblib.load(f)
feature_importance = pd.Series(model.feature_importances_ / sum(model.feature_importances_), index=model.feature_names_)
Creating a Model Version#
We’ll use the create_tabular_model_version method. Calling it, we can create both our
model, our model version and define the reference data with one call. We’ll also let Deepchecks know this is a
binary classification task, so we will set the task_type argument. We’ll also set the default monitoring
frequency to be a month, to match our data which is collected on a monthly basis. Lastly, in order to fully define
the reference, we must also pass model predictions for the reference data. For classification tasks, it’s highly
recommended to also pass predicted probabilities, in order to be able to calculate metrics such as ROC AUC that are
calculated on these probabilities.
ref_predictions = model.predict(train_df[features])
ref_predictions_proba = model.predict_proba(train_df[features])
model_name = 'Loan Defaults - Example'
It is also recommended to explicitly tell deepchecks about the classes in your task using the
model_classes argument. These names must match the labels you are sending (and the ones the model is predicting),
and must be sorted alphanumerically.
model_version = dc_client.create_tabular_model_version(model_name=model_name, version_name='ver_1',
schema=schema_file_path,
feature_importance=feature_importance,
reference_dataset=train_dataset,
reference_predictions=ref_predictions,
reference_probas=ref_predictions_proba,
task_type='binary',
model_classes=[0, 1],
monitoring_frequency='month')
Model Loan Defaults - Example was successfully created!. Default checks, monitors and alerts added.
Model version ver_1 was successfully created.
/home/runner/work/monitoring/monitoring/.venv/lib/python3.11/site-packages/deepchecks_client/tabular/client.py:407: UserWarning:
Maximum size allowed for reference data is 100,000, applying random sampling
Reference data uploaded.
Now we know our model, model version and reference data where set, and we’re ready to start uploading production data.
Uploading Production Data#
Once in production, uploading data can be done either sample by sample, or by batch. To read more, please refer to the Production Data Guide. Here we’ll show how to use the batch upload method. In our example we already saved the production data for all time stamps in a csv file on figshare.
prod_data = pd.read_csv('https://figshare.com/ndownloader/files/39316157', parse_dates=['issue_d'])
We’ll change the original timestamps so the samples are recent
import datetime
time_delta = pd.Timedelta(pd.to_datetime(datetime.datetime.now()) - prod_data['issue_d'].max()) - pd.Timedelta(2, unit='d')
prod_data['issue_d'] = prod_data['issue_d'] + time_delta
prod_data['issue_d'].unique()
<DatetimeArray>
['2022-12-24 16:04:43.485245', '2023-01-24 16:04:43.485245',
'2023-02-24 16:04:43.485245', '2023-03-26 16:04:43.485245',
'2023-04-26 16:04:43.485245', '2023-05-26 16:04:43.485245',
'2023-06-26 16:04:43.485245', '2023-07-27 16:04:43.485245',
'2023-08-24 16:04:43.485245', '2023-09-24 16:04:43.485245',
'2023-10-24 16:04:43.485245', '2023-11-24 16:04:43.485245',
'2023-12-24 16:04:43.485245', '2024-01-24 16:04:43.485245',
'2024-02-24 16:04:43.485245', '2024-03-25 16:04:43.485245',
'2024-04-25 16:04:43.485245', '2024-05-25 16:04:43.485245',
'2024-06-25 16:04:43.485245', '2024-07-26 16:04:43.485245',
'2024-08-23 16:04:43.485245', '2024-09-23 16:04:43.485245',
'2024-10-23 16:04:43.485245', '2024-11-23 16:04:43.485245',
'2024-12-23 16:04:43.485245', '2025-01-23 16:04:43.485245',
'2025-02-23 16:04:43.485245', '2025-03-25 16:04:43.485245',
'2025-04-25 16:04:43.485245', '2025-05-25 16:04:43.485245']
Length: 30, dtype: datetime64[ns]
Uploading a Batch of Data#
prod_predictions = model.predict(prod_data[train_dataset.features].fillna('NONE'))
prod_prediction_probas = model.predict_proba(prod_data[train_dataset.features].fillna('NONE'))
We’ll also convert out pandas datetime column to int timestamps (seconds since epoch), which is the time format expected by deepchecks.
model_version.log_batch(sample_ids=prod_data['id'],
data=prod_data.drop(['issue_d', 'id', 'loan_status'], axis=1),
timestamps=(prod_data['issue_d'].astype(int) // 1e9).astype(int),
predictions=prod_predictions,
prediction_probas=prod_prediction_probas)
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
10000 new samples sent.
5019 new samples sent.
Upload finished successfully but might take time to ingest into the system, see http://127.0.0.1:8000/configuration/models for status.
Uploading The Labels#
The labels are global to the model, and not specific to a version. Therefore, to upload them we need the model client. You can do this directly after uploading the predictions, or at any other time.
model_client = dc_client.get_or_create_model(model_name)
model_client.log_batch_labels(sample_ids=prod_data['id'], labels=prod_data['loan_status'])
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
10000 labels sent.
5019 labels sent.
Making Sure Your Data Has Arrived#
If you’re not sure if your data has arrived, please refer to the relevant section in the Production Data guide.
Analyzing Using Deepchecks#
Now that you have our data in Deepchecks, you can start analyzing it. Has the model been performing well? The economy has been entering a mild recession recently and you managers have raised concerns that this may have affected your model’s ability to correctly predict loan defaults. You set to investigate.
Dashboard & Alerts - Finding Drift#
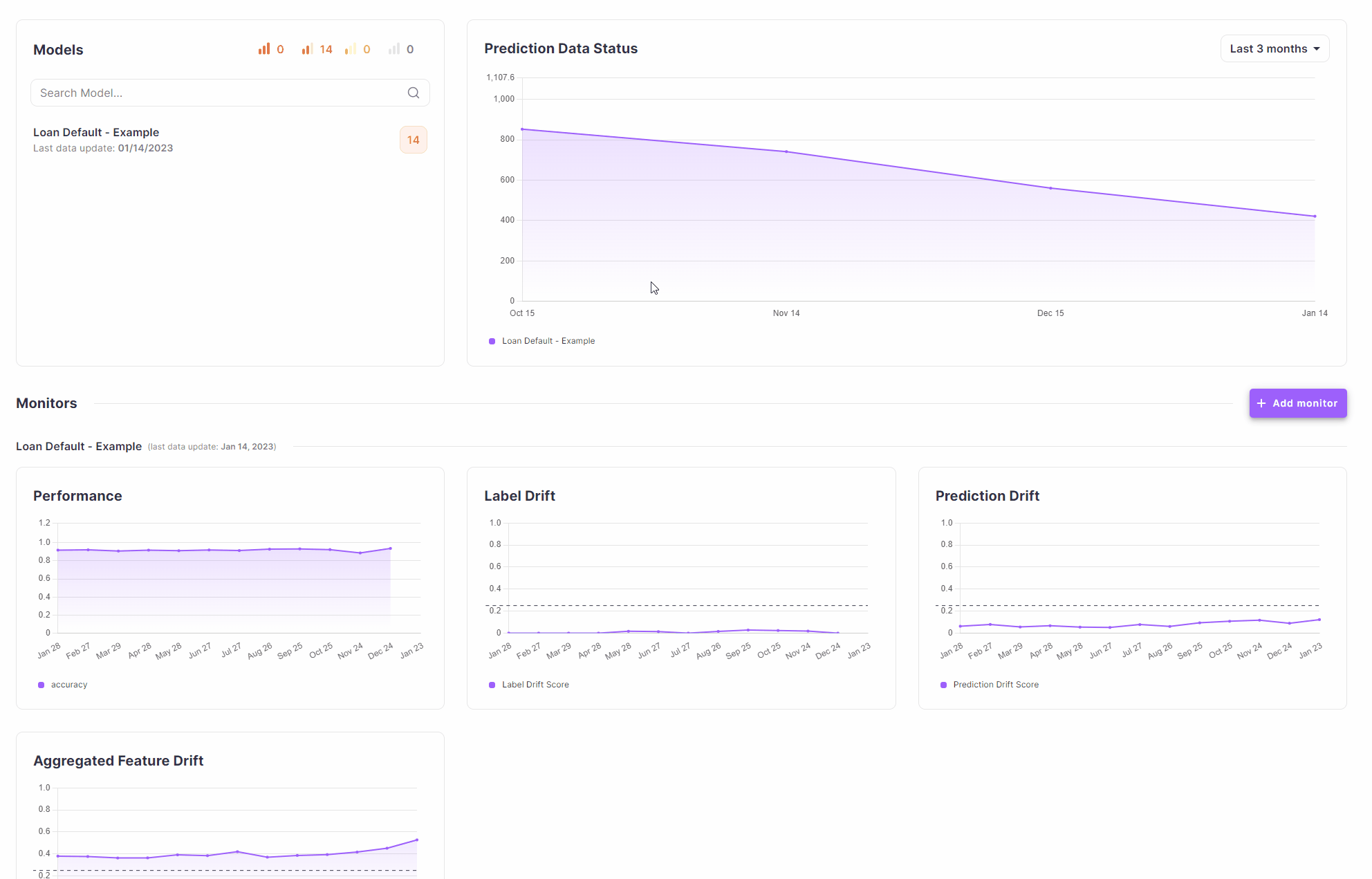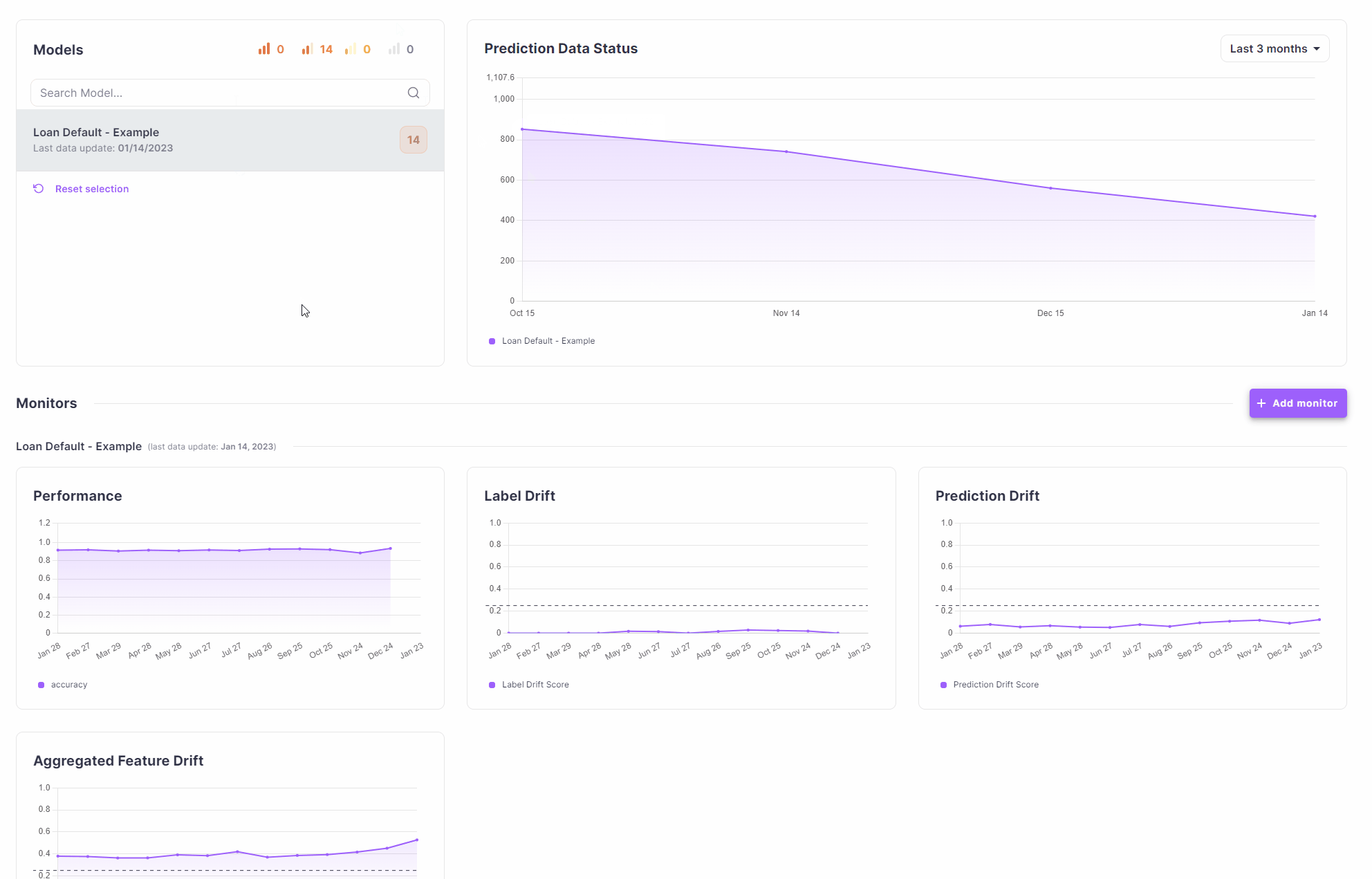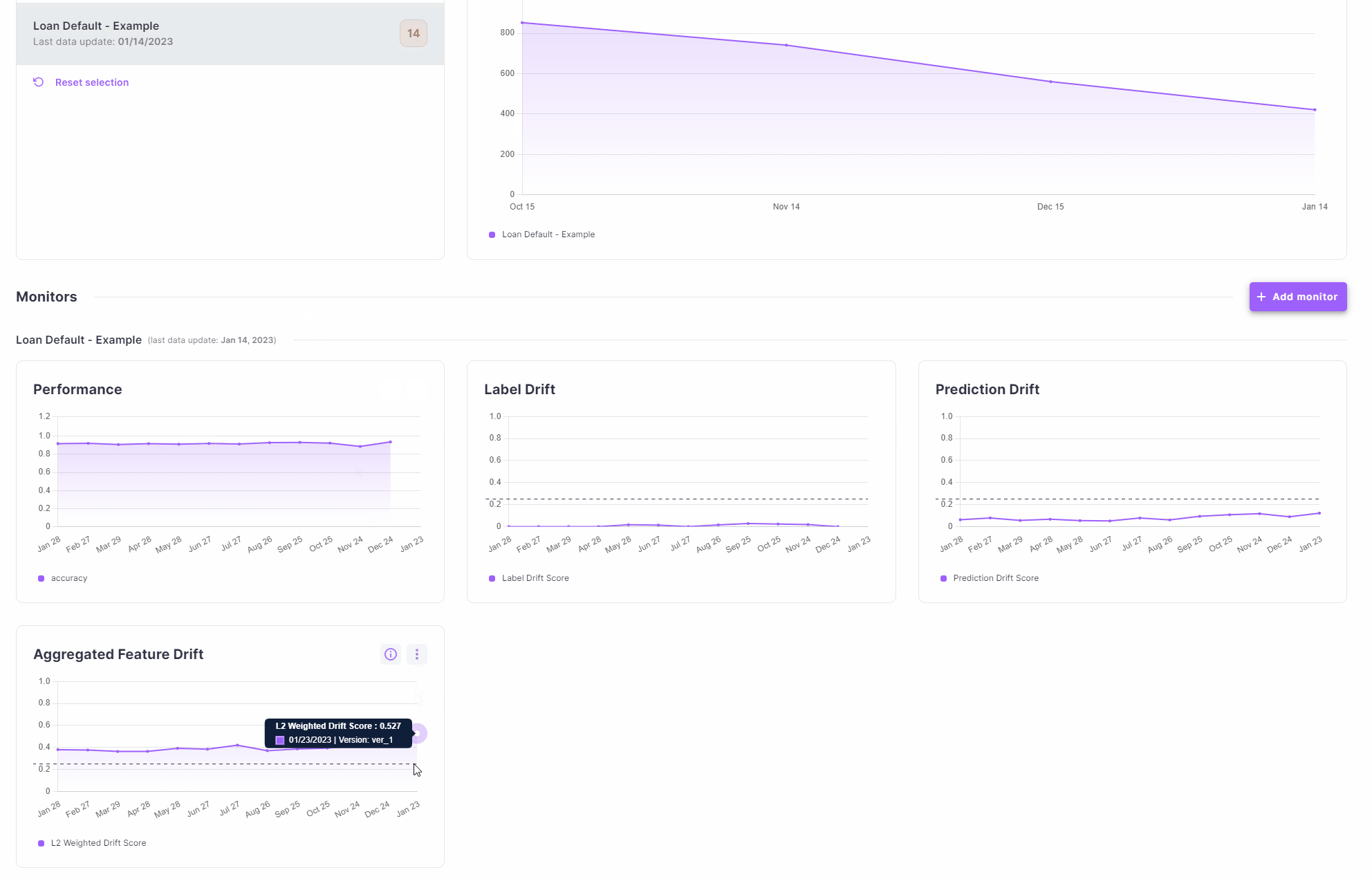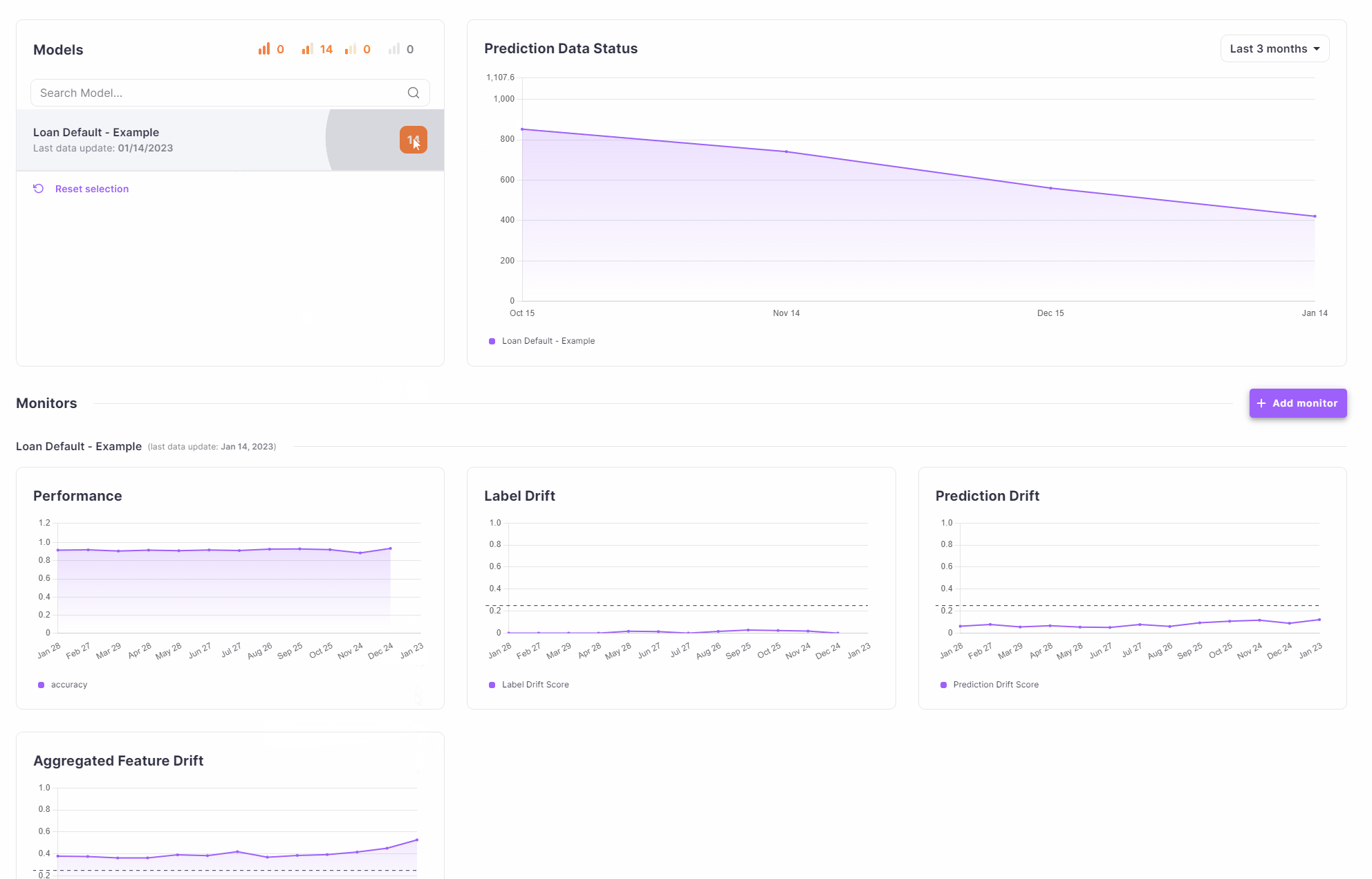
When you log in to Deepchecks, you’ll be greeted by the Dashboard, in which you can view all the monitors defined for
your models. Selecting our Loan Default - Example model, we see the default monitors and their corresponding
default alert rules. We can also see that the Aggregate Feature Drift monitor has exceeded the default alert rule
threshold, and has triggered an alert. We can click on the alert to see more details.
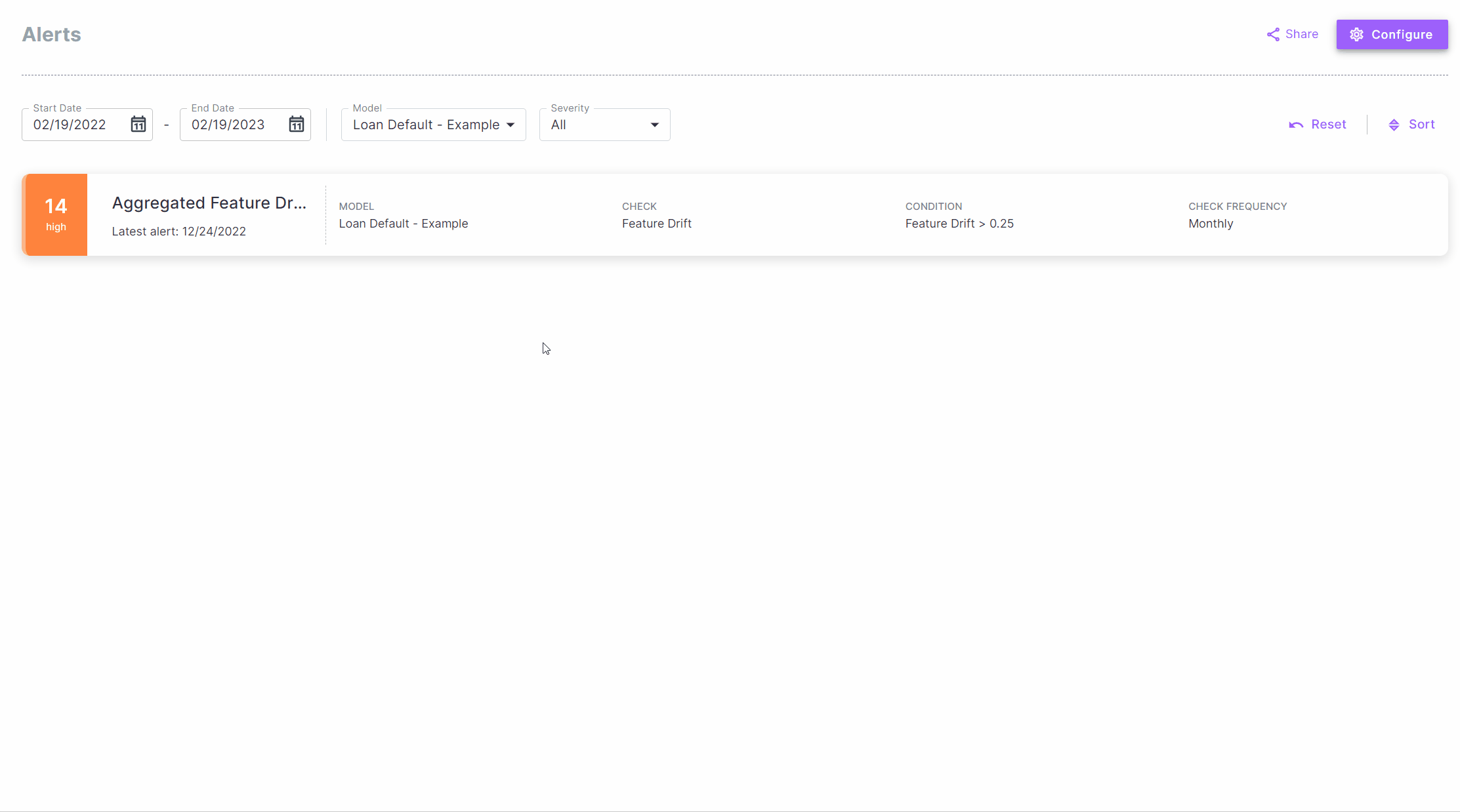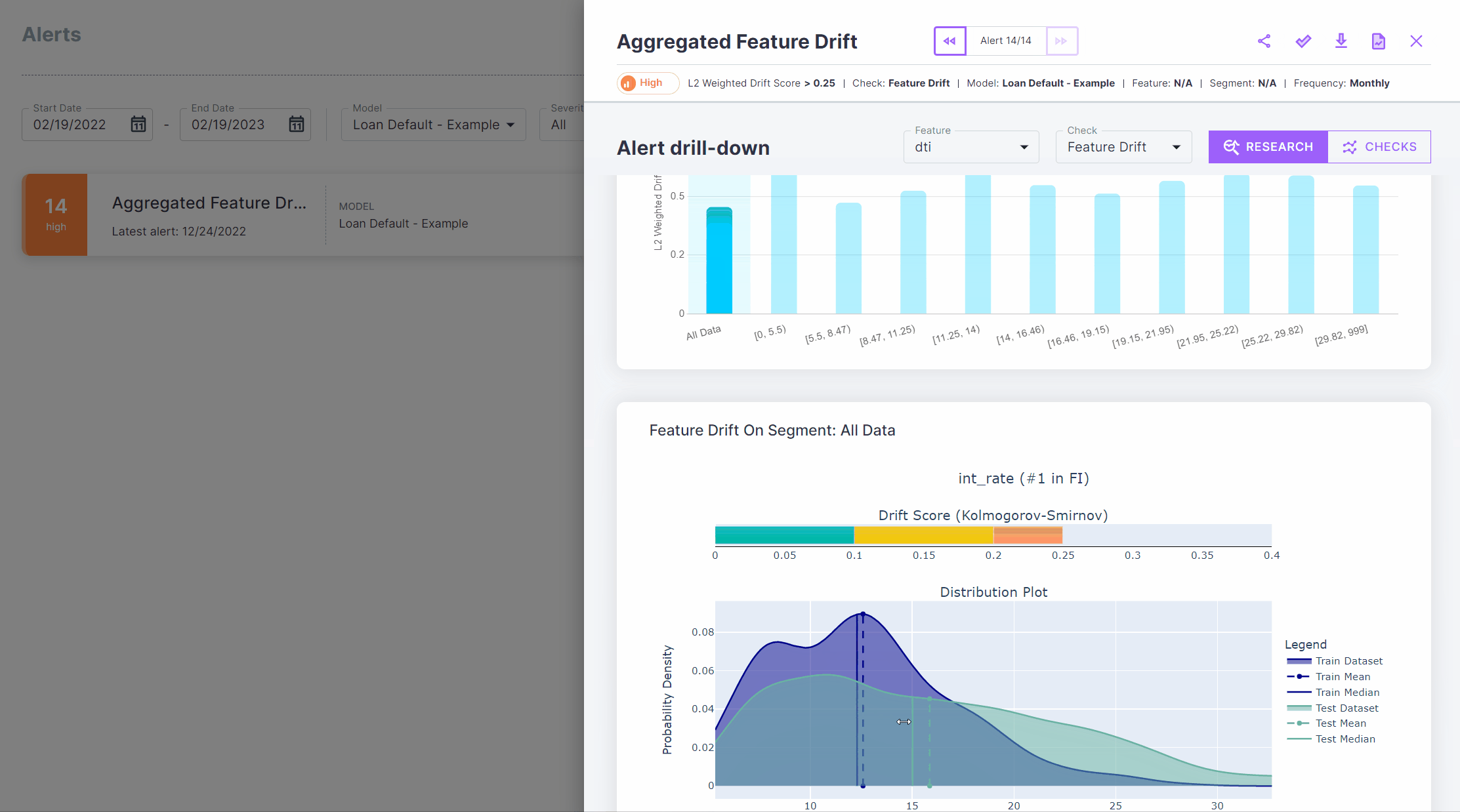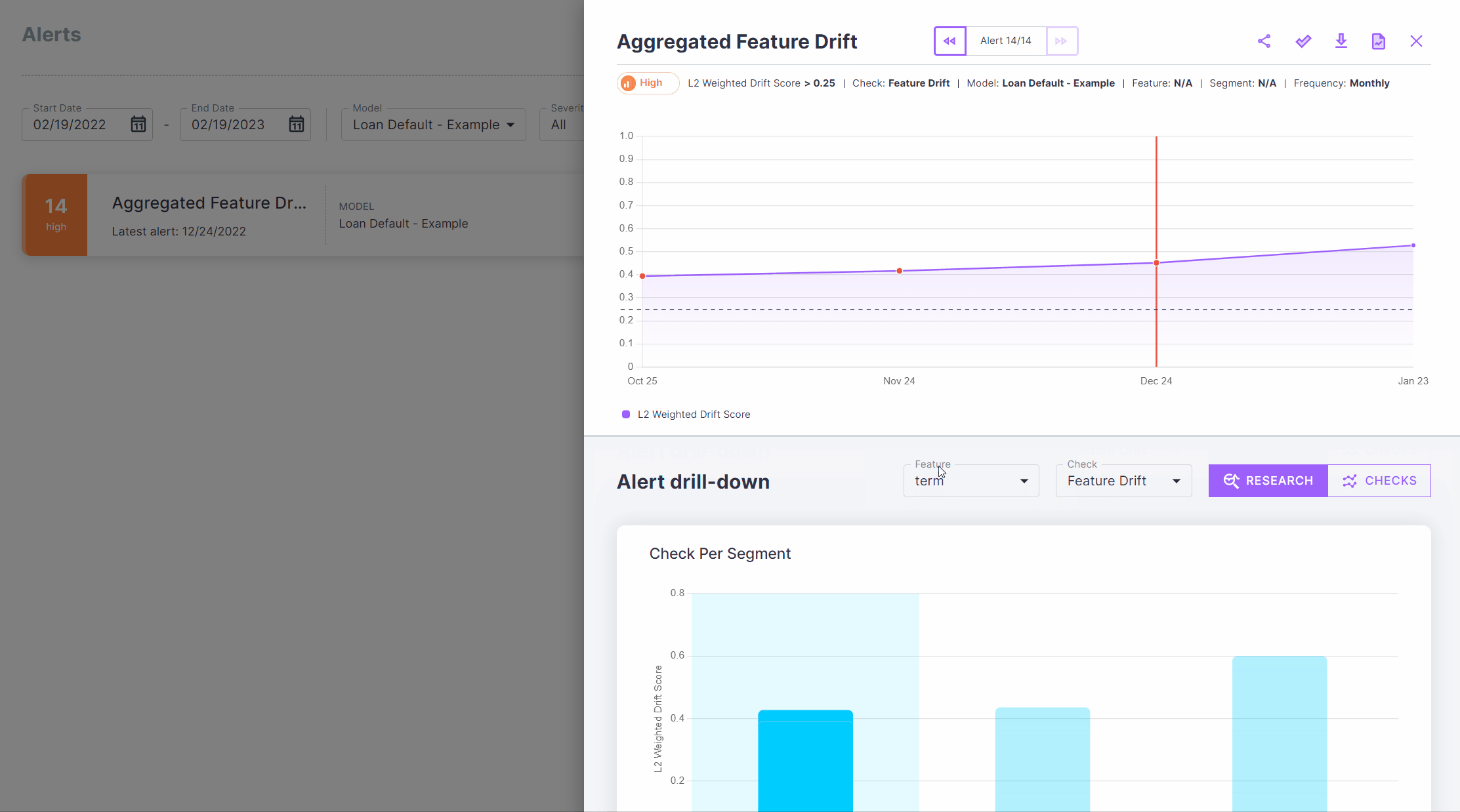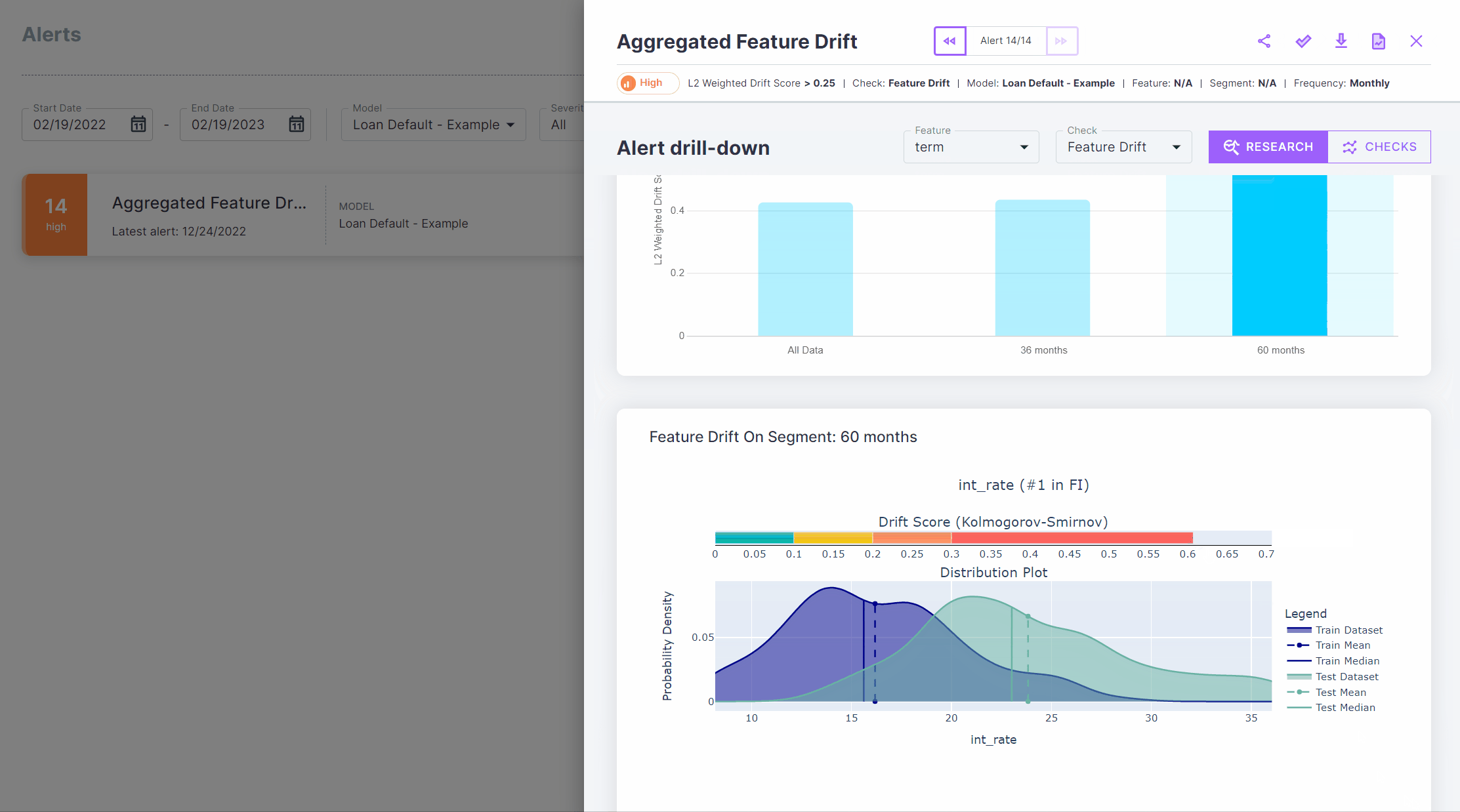
Once in the alert screen, you can see the list of all current alerts on your model. Clicking on that alert will open an alert analysis screen. This screen has three main components - the monitor history graph, the segment explorer and the check details.
The monitor history graph shows the monitor’s value over time and the point at which the alert was triggered.
The segment explorer allows you to see what was the value of the check at the time of the alert, in different segments of the data.
The check details section shows the details of the check that triggered the alert.
In this case, you can see in the check details section that there is significant drift in the int_rate feature,
whose average has increased dramatically. This is the case for the “All Data” segment, but does this issue originate
from a specific segment? Let’s find out.
Segmenting on the term feature, we can easily see that the drift is coming mostly from long term loans. This is
not surprising, as the economy has been entering a mild recession recently, and long term loans are more sensitive to
increases in interest rates.
Analysis - Detecting Integrity Issues#
Once you got this major drift issue under control, you may be interested in looking for other issues in your data. For freely exploring the status, you can head to the Analysis screen. There you can run any of the checks you defined for your model over different time periods and segments and easily change the parameters of the checks.
Scrolling down the list of checks, you’ll find that the Percent of Nulls check had some non-zero values in the
past few months.
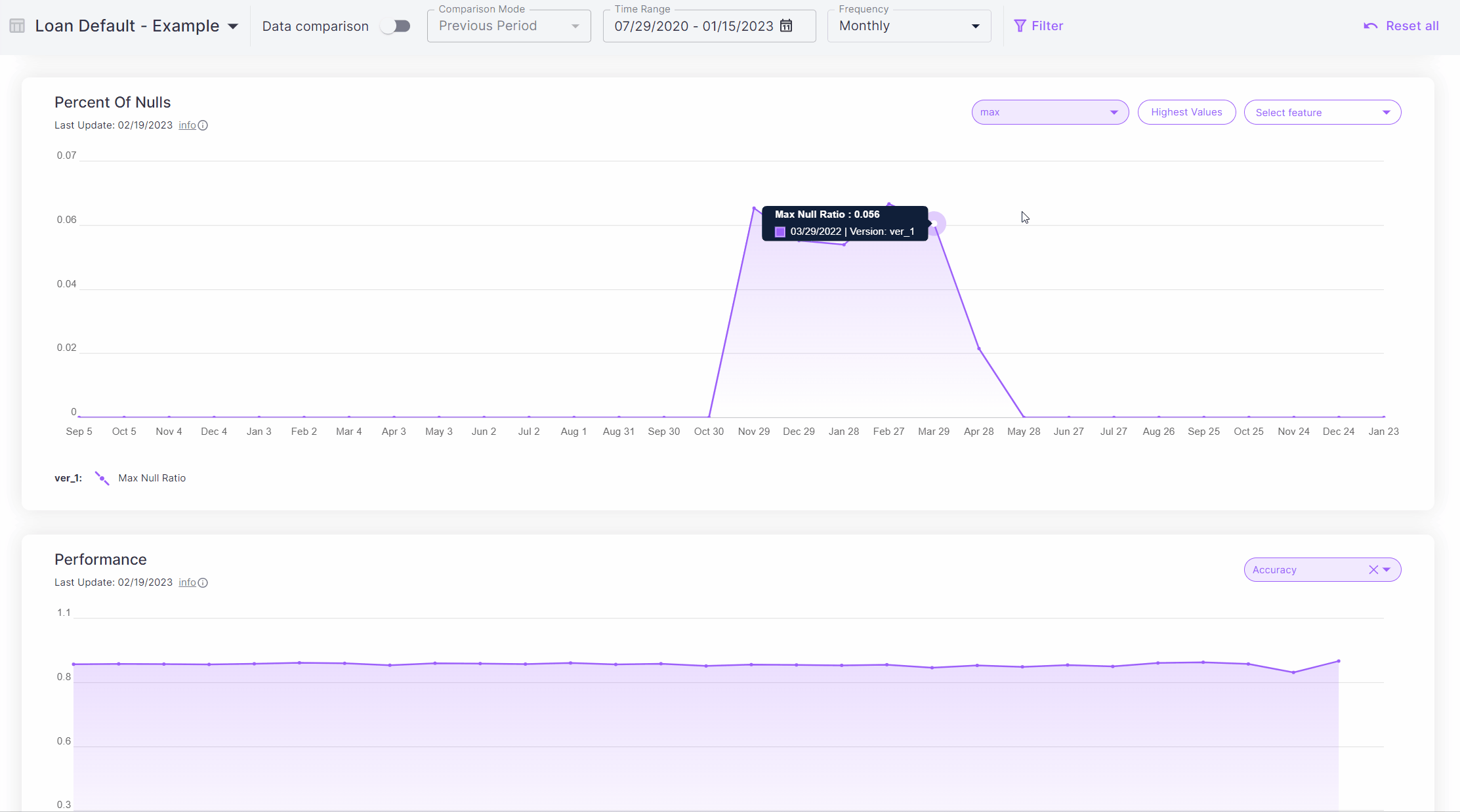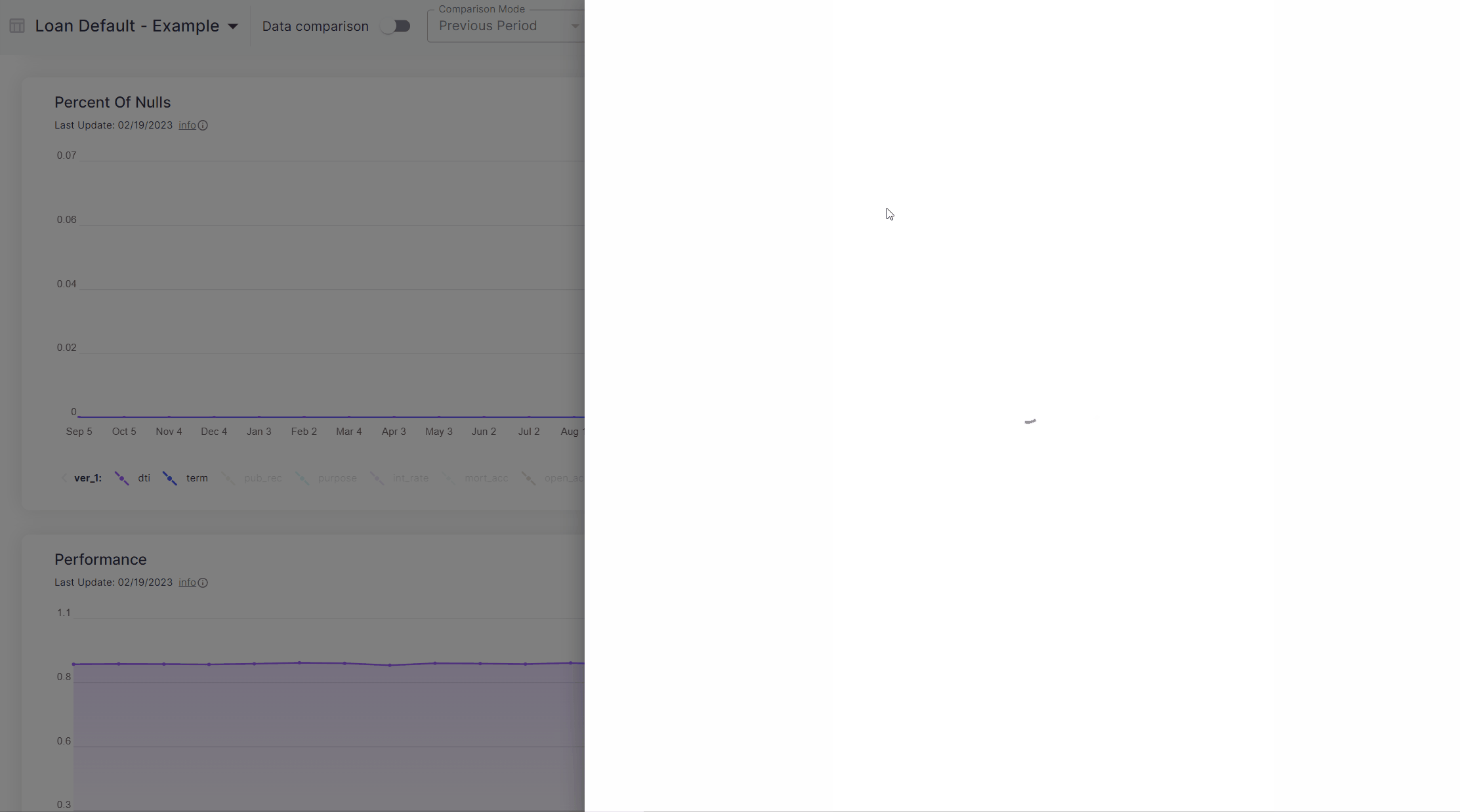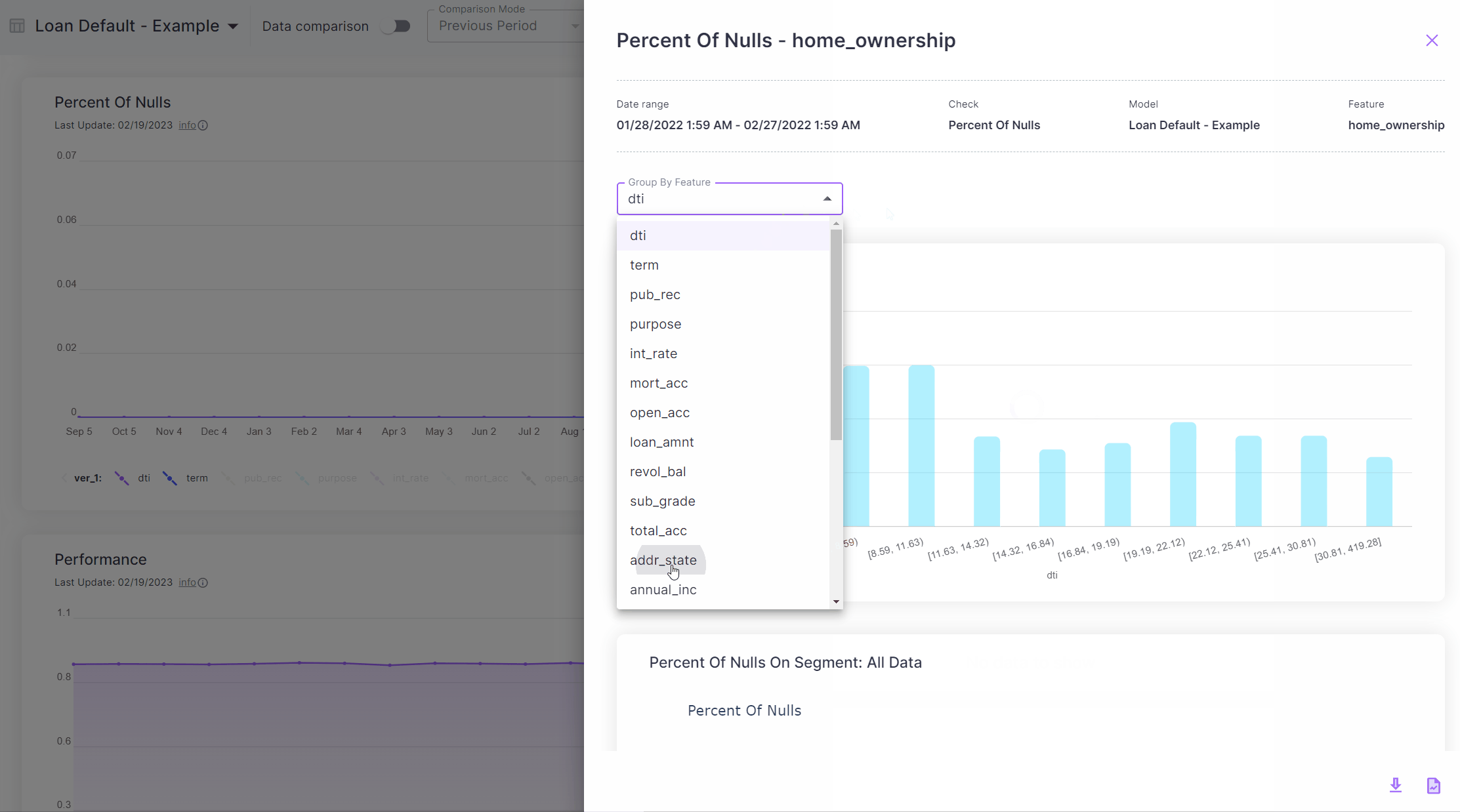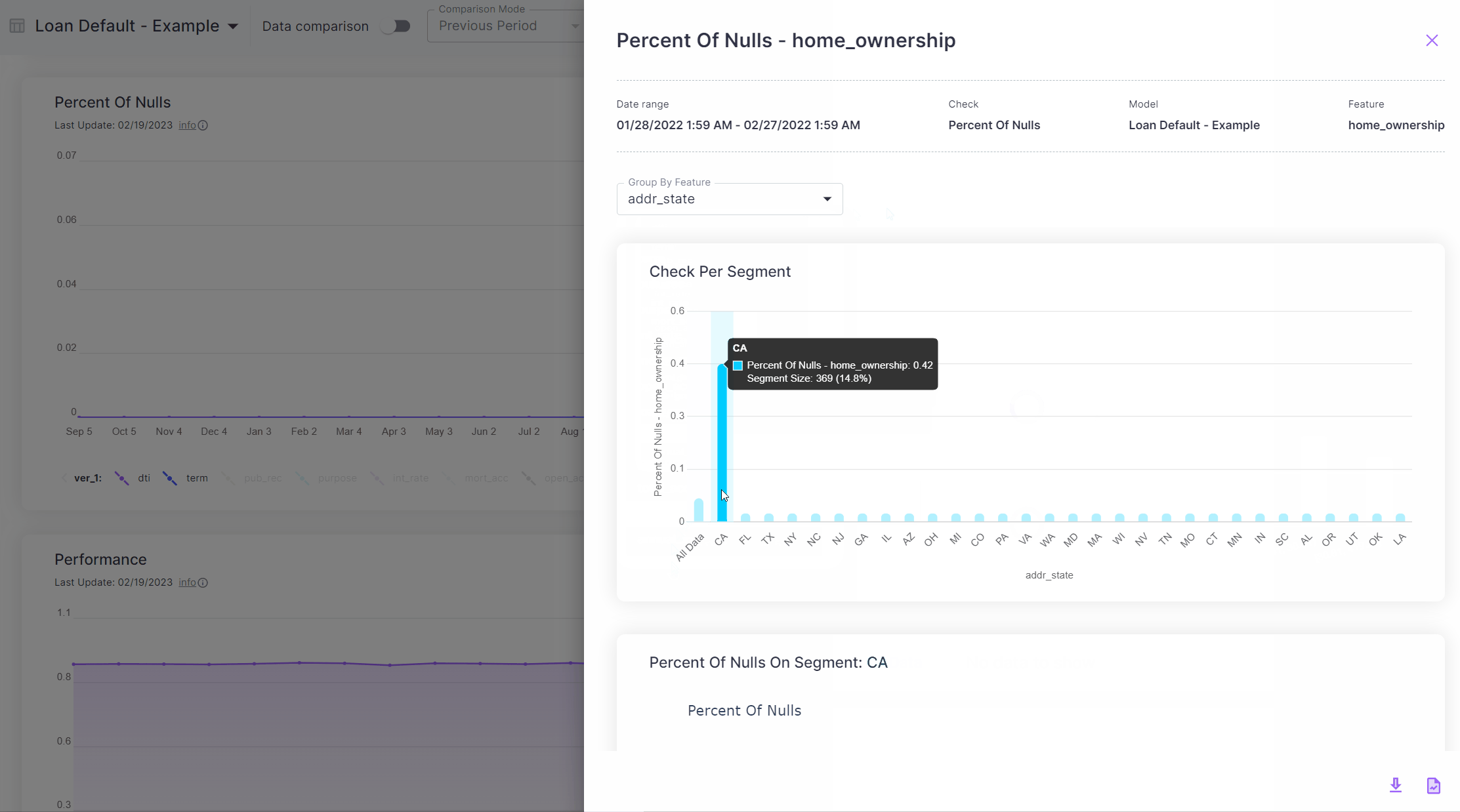
Clicking the check at one of the times it had been non-zero, we can see that we have some nulls in the
home_ownership feature. Furthermore, using the “Check Per Segment” part of the screen we can see the value of the
check when the data is segmented by various features. In this case, we can see that the nulls are happening
exclusively in loans made in California. Time to talk to the Data Engineering team! Seems like there has been some
issue with the data pipeline coming from the state of California.
Updating Labels#
In many use-cases, such as with Loan status, the labels may arrive way after the model prediction was made. In these cases it is possible to update the labels of samples that where previously unlabeled. Let’s say for example that we have just learned of a few loans that where paid in full, then we can update their labels using the following function:
labels_to_update = [87609, 87640, 87751, 93415, 87574, 87446, 87703, 87627, 93162,
87405, 87549, 87681, 93893, 87392, 87390, 87536, 93116, 87540,
87669, 87608, 87743, 87650, 87587, 87545, 87657, 87702, 87398,
87673, 87408, 87685, 92032, 88162, 87515, 87723, 87537, 87710,
87761, 87445, 87554, 87463, 87521, 87659, 87569]
model_client.log_batch_labels(sample_ids=labels_to_update, labels=[0] * len(labels_to_update))
43 labels sent.
Cleaning up#
If you wish to delete this model from your environment, you can do that using the delete_model function.
CAUTION: This will delete the model, all model versions, and all associated datasets.
# dc_client.delete_model(model_name)
Total running time of the script: (4 minutes 9.703 seconds)